Is Data Normalization always needed?
Data Normalization, also known as feature scaling is often the first step in the preprocessing pipeline before running the machine learning model. Not all ML algorithms required normalized data, but it rarely hurts.
- ML Models that can handle features with drastically different scales
- Decision-Tree based models
- ML Models that will benefit from normalization
- SVM, KNN, Logistic Regression
- Neural Networks
- Clustering algorithms like K-Means, K-Medoids, DBSCAN
- Feature Extraction(PCA, LDA)
Hence it is a good practice to normalize the data before passing it on to the machine learning pipeline
Types of normalization
- Min-Max Scaling - Maps a numerical value x to the [0, 1] interval
- Standardization, also called Z-Score Normalization - Maps a numerical value to a new distribution with mean 0 and standard deviation = 1
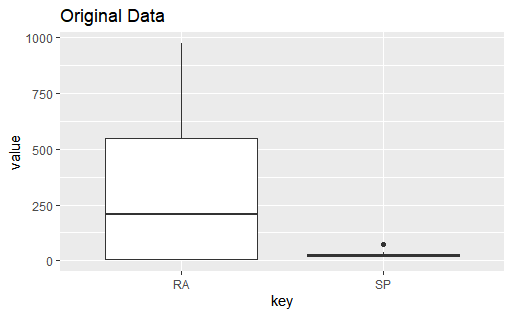
The scales are so different the inter quartile ranges are barely close, lets normalize and check again.
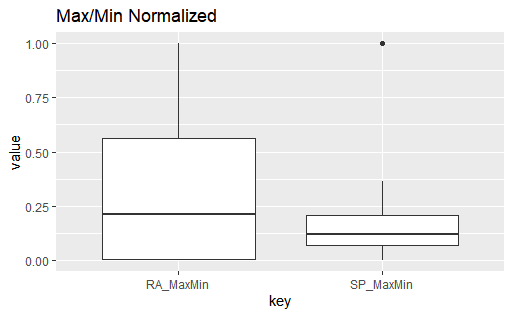
The two interquartile ranges are similar, but lets check results with Z-score normalization
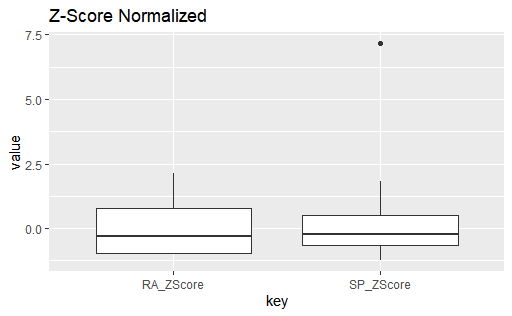
Z-score normalization brought the two interquartile ranges to a similar scale, meaning that neither feature dominates the other one